Today I made a structural shift in my OpenClaw setup with the help of Codex-5.3. For those who know my current architecture, I’ve been running Codex CLI in the backend to manage the OpenClaw instance on my Pi. Over time we’ve built it into a complete knowledge holder for everything related to OpenClaw, and that accumulated context is what made this change possible.
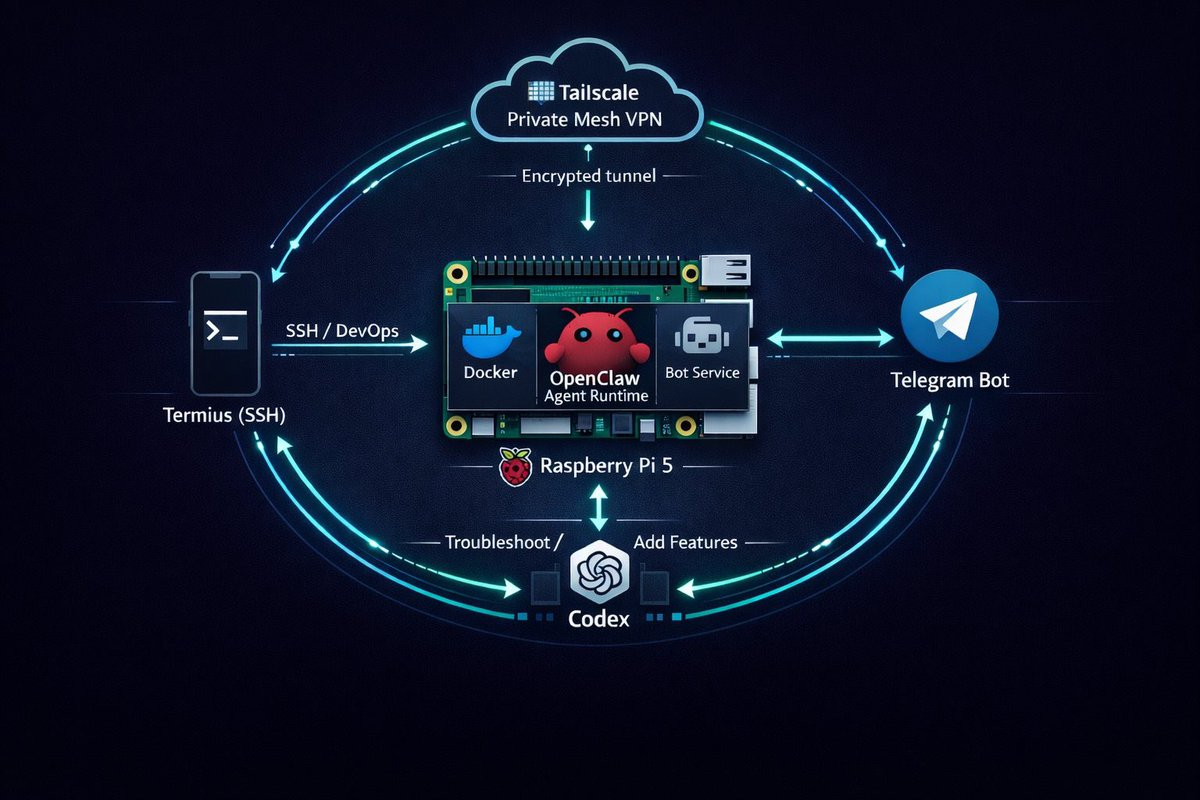
I had a single strong agent running KOL and content execution, and it worked well. The strain started when I pushed it beyond that scope. Content strategy, software architecture, and private daily support were all forced to share the same brain.
That does not scale.
So we moved to a team model:
main(Chief): chief-of-staff and orchestratorkol: brand/content specialistcoder(Builder): coding and architecture specialistprivate(Companion / care): personal support specialist
The non-negotiable constraint was simple: keep the existing system stable while migrating.
The Design Decision
The core design choice was not “add more bots.”
It was: separate role, memory, and operating policy by agent.
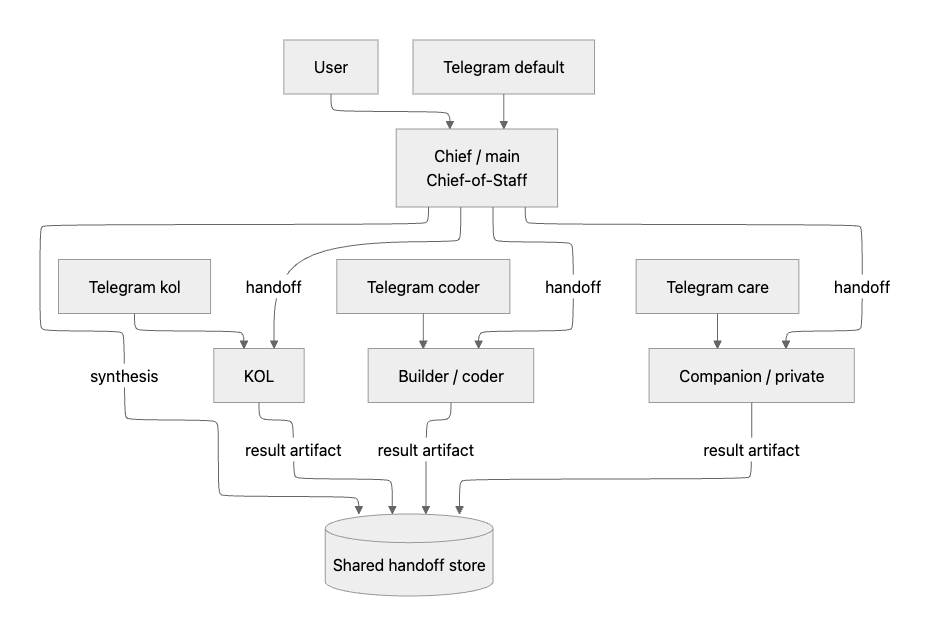
Context Isolation: The Real Boundary
Each specialist gets a separate context pack:
SOUL.mdIDENTITY.mdUSER.mdTOOLS.mdMEMORY.mdAGENTS.md
This is what prevents agent drift. Without this separation, specialists collapse back into one generalist voice.
Communication Pattern: Handoffs, Not Vibes
We used a strict handoff channel:
~/.openclaw/shared/handoffs/inbox/~/.openclaw/shared/handoffs/outbox/~/.openclaw/shared/handoffs/archive/
Flow:
- Chief writes a structured handoff request.
- Specialist executes and writes a structured response.
- Chief synthesizes and reports back.
If a delegated task has no valid handoff_id, specialist rejects it with:
HANDOFF_REQUIRED: missing or invalid handoff_id
That single rule eliminated most delegation ambiguity.
Migration Plan We Used
Phase 1: Bootstrap specialists without touching live routing
We created kol, coder, and private with isolated workspaces and identity files.
No channel cutover yet.
Safety checks:
- backup
openclaw.json - snapshot agents before and after
- assert
mainstays default
Phase 2: Split old main persona into orchestrator + specialist
main was still carrying old KOL framing. We migrated main to Chief (chief-of-staff role), then moved content-specific context and memory to kol.
Guideline:
mainkeeps orchestration memorykolkeeps content strategy + daily journal continuity
Phase 3: Split Telegram routing by account
We added dedicated account bindings:
telegram accountId=default -> maintelegram accountId=kol -> koltelegram accountId=coder -> codertelegram accountId=care -> private
In multi-account mode, explicit bindings are mandatory. Implicit defaults are where routing bugs hide.
Phase 4: Move monitor ownership to the right specialist
KOL monitors were migrated from main to kol.
Also, delivery was pinned with delivery.accountId=kol.
Important: setting agentId=kol is not enough if delivery account still falls back to default.
Phase 5: Hardening delegation runtime behavior
We hit two real failure modes:
- Chief simulated specialists with internal
mainsubagents. sessions_spawncalls missingagentId, which defaulted tomain.
Fixes:
- allow specialist agents in
mainspawn policy - require explicit
sessions_spawn(agentId=...) - verify returned
childSessionKeyprefix (agent:kol|coder|private) - block completion when handoff artifacts are missing
End-to-End Test That Actually Proves It Works
We tested the system as a system:
- Send one task to Chief requiring all specialists.
- Confirm Chief delegates.
- Confirm each specialist returns via handoff artifacts.
- Confirm Chief synthesizes final output.
Audit evidence:
- child sessions are specialist-prefixed, not
agent:main:subagent:* - one inbox + one outbox handoff artifact per specialist
- final synthesis references specialist outputs
- cron jobs show aligned
agentIdanddelivery.accountId
Pitfalls We Hit (and How We Fixed Them)
1) openclaw command available in some shells, missing in others
Cause: npm globals under ~/.npm-global/bin were not always on runtime PATH.
Fix we used: stable shims in ~/.local/bin for openclaw and codex.
2) KOL monitor still showing up under Chief
Cause: stale job config and/or missing delivery.accountId.
Fix: patch job routing so both are explicit:
agentId=koldelivery.accountId=kol
3) Delegation looked correct but was fake
Cause: orchestration prompt allowed simulation and runtime defaulted to main.
Fix: enforce explicit agent spawn and verify session keys.
4) Handoff protocol bypass
Cause: old prompts did not require handoff metadata.
Fix: fail-closed behavior and mandatory handoff_id.
5) Restart noise created false alarms
Symptom: temporary websocket close (1006) right after restart.
Fix: wait for gateway probe to return OK before declaring failure.
If You Want to Reproduce This, Don’t Manually Click Through Everything
Use a coding agent (Claude Code, Codex, etc.) and give it a clear contract:
- Plan migration in phases with rollback points.
- Backup config before each write.
- Create isolated identity packs per agent.
- Set explicit channel/account bindings.
- Migrate cron ownership and delivery account IDs.
- Prove delegation with artifacts and session-key evidence.
- Run one end-to-end orchestration test and produce an audit report.
If the agent cannot produce evidence artifacts, treat the migration as incomplete.
Closing
The shift from one agent to many is not a tooling problem. It is an operating model problem.
What worked for us was:
- clear hierarchy
- isolated context
- explicit routing
- hard delegation contracts
- evidence-based testing
That gave us specialist depth without losing the reliability of the original setup.