A response to the observation that “coding agents are general agents” and that program synthesis will outperform hand-crafted vertical-specific agents.
The Post
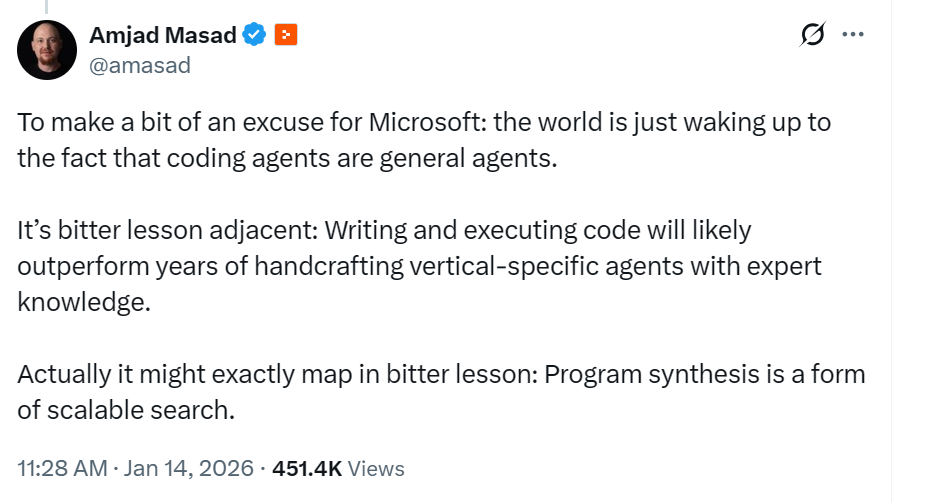
The Thesis
The tweet makes a compelling point: coding agents that write and execute code represent a form of scalable search. Rather than encoding years of expert knowledge into prompts and rules, let the agent explore the solution space through code generation and execution. This is “bitter lesson adjacent”—general methods that leverage computation outperform hand-crafted approaches.
I agree with the direction. But after building production agents that query databases, orchestrate workflows, and operate in specialized domains, I’ve found an important nuance: the bitter lesson doesn’t eliminate hand-crafting, it shifts what you hand-craft.
And that shift reveals where the real moat lies.
The Weak Feedback Problem
Consider an agent that answers business questions by querying data. The user asks: “Who are the best performers this quarter?”
A pure exploration approach would:
- Generate candidate queries
- Execute them
- Observe results
- Iterate until… what?
Here’s the problem: syntactically valid code can return completely wrong answers. The query runs, returns rows, looks reasonable—but answers a different question than the user asked.
In game-playing AI, the feedback signal is unambiguous: win or lose. In code generation with tests, feedback is clear: tests pass or fail. In real-world agents operating on business data, what’s the signal?
- Code executes without error? Weak.
- Results are non-empty? Weak.
- Output looks reasonable? Weak.
None of these tell you whether “best performers” means highest revenue, most volume, fastest completion, or lowest error rate. The agent can explore forever without converging on the right answer—unless it knows what “right” means.
You Can’t Escape Evaluation
The bitter lesson says: don’t hand-craft the solution, let search find it. But search without a fitness function is random walk.
The feedback signals that actually work are:
- Golden datasets - curated question/answer pairs where humans defined “correct”
- User feedback - explicit corrections, thumbs up/down
- Domain constraints - business rules that must hold
Notice something? These all require human input. You’re not eliminating hand-crafting—you’re shifting it from solutions to evaluation.
| Traditional Approach | Bitter Lesson Approach |
|---|---|
| Hand-craft solutions (rules, templates, workflows) | Hand-craft evaluation (golden data, feedback loops) |
| Agent follows rules | Agent searches for solutions that pass eval |
The bitter lesson is correct that search finds solutions humans wouldn’t anticipate. But someone still has to define what “correct” means.
A Hybrid Architecture
The practical path forward is hybrid:
Seed, don’t script. Start with minimal domain knowledge—enough to bootstrap. Core definitions, key patterns, essential constraints. This is your seed.
Grow from feedback. Every evaluation run produces learning signals:
- Failures reveal gaps in understanding
- Successes become cached patterns
- User corrections teach the system directly
Cache what works. The “knowledge base” becomes a cache of patterns that passed evaluation, not a hand-crafted rulebook. Entries track their provenance: where they came from, how often they’re used, their success rate.
Decay what doesn’t. Patterns with declining success rates get deprecated. The system forgets what stops working.
┌─────────────────────────────────────────────────────┐
│ FEEDBACK LOOP │
│ │
│ Eval Results ──┐ │
│ │ │
│ User Feedback ─┼───▶ Learning ───▶ Knowledge │
│ │ Loop Cache │
│ Exec Success ──┘ (grows) │
│ │
└─────────────────────────────────────────────────────┘
This aligns with the bitter lesson: the knowledge cache is learned, not scripted. But it’s learned from evaluation signals that humans defined.
The Role of AI in the Loop
Here’s where it gets interesting. The feedback loop itself can be AI-assisted:
- Evaluation fails on a set of inputs
- AI analyzes the failures, suggests what’s missing from the knowledge cache
- Domain experts validate the suggestions
- High-confidence suggestions auto-apply; others queue for review
- System improves, repeat
The human role shifts from “author all the rules” to “curate the evaluation set and validate AI suggestions.” This scales better—humans define what correct means, AI figures out how to get there.
Where the Moat Actually Is
This brings us to a strategic question I’ve been thinking about: as AI agents become the orchestration layer, where does value accrue?
General AI agents are becoming commoditized. The orchestration layer—planning, tool use, code generation—is increasingly table stakes. What’s not commoditized is the domain-specific context that agents need to operate effectively.
For any agent operating in a specialized domain, the general capability (generate code, execute it, iterate) is replaceable. What’s not replaceable:
- Your data - the actual records, history, ground truth
- Your semantics - what terms mean in your context, which metrics matter, how entities relate
- Your evaluation signal - the definition of “correct” in your domain
The bitter lesson says: don’t hand-craft solutions, let search find them. But search needs a fitness function. That fitness function—the definition of “correct” in your domain—is the moat.
┌─────────────────────────────────────────────────────────────┐
│ VALUE STACK │
│ │
│ ┌─────────────────────────────────────────────────────┐ │
│ │ Orchestration (agents, planning, tool use) │ ← Commoditizing │
│ └─────────────────────────────────────────────────────┘ │
│ │ │
│ ▼ │
│ ┌─────────────────────────────────────────────────────┐ │
│ │ Semantics (what terms mean, valid operations) │ ← Moat │
│ └─────────────────────────────────────────────────────┘ │
│ │ │
│ ▼ │
│ ┌─────────────────────────────────────────────────────┐ │
│ │ Data (records, history, ground truth) │ ← Moat │
│ └─────────────────────────────────────────────────────┘ │
│ │ │
│ ▼ │
│ ┌─────────────────────────────────────────────────────┐ │
│ │ Evaluation (what "correct" means here) │ ← Moat │
│ └─────────────────────────────────────────────────────┘ │
│ │
└─────────────────────────────────────────────────────────────┘
The bitter lesson commoditizes the top layer. The bottom three become more valuable, not less.
Why This Matters Now
LLMs are good enough to explore solution spaces through code generation. They’re not yet reliable enough for fully autonomous exploration in production systems where wrong answers have consequences.
The hybrid approach bridges this gap:
- Today: Humans seed core knowledge, AI explores within guardrails, feedback tightens the loop
- Near-term: More auto-apply, less human validation, as confidence in the learning loop grows
- Long-term: The bitter lesson wins at the orchestration layer. Domain semantics and evaluation become the differentiator.
Conclusion
The tweet is directionally correct: code-generating agents performing scalable search will outperform hand-crafted expert systems. The orchestration layer is being commoditized.
But two things remain irreplaceable:
- Evaluation - Someone must define what “correct” means. The bitter lesson shifts hand-crafting from solutions to evaluation.
- Domain semantics - Agents need context to operate effectively. Your data, your definitions, your constraints—these become the product surface.
For anyone building vertical agents, the strategic question isn’t “how do we add AI capabilities?” It’s “how do we make our domain knowledge consumable by AI?”
The path forward:
- Build robust evaluation infrastructure (golden datasets, feedback loops)
- Treat your semantic layer as a first-class asset—well-defined, predictable, evolvable
- Let AI explore, but ground it in your domain truth
- Own the definition of “correct” in your vertical
The bitter lesson commoditizes capabilities. Domain knowledge—your data, your semantics, your evaluation signal—becomes the moat.